Support Vector Machine
Class Reference
- class pykitml.SVM(input_size, output_size, reg_param=0)
Implements Support Vector Machine with Linear Kernel.
Note
The outputs/targets in the training/testing data should have
-1instead of0for training. See example for more details.- __init__(input_size, output_size, reg_param=0)
- Parameters:
input_size (int) – Size of input data or number of input features.
output_size (int) – Number of categories or groups.
reg_param (int) – Regularization parameter for the model, also known as ‘weight decay’.
- feed(input_data)
Accepts input array and feeds it to the model.
- Parameters:
input_data (numpy.array) – The input to feed the model.
- Raises:
ValueError – If the input data has invalid dimensions/shape.
Note
This function only feeds the input data, to get the output after calling this function use
get_output()orget_output_onehot()
- get_output()
Returns the output activations of the model.
- Returns:
The output activations.
- Return type:
numpy.array
- get_output_onehot()
Returns the output layer activations of the model as a one-hot array. A one-hot array is an array of bits in which only one of the bits is high/true. In this case, the corresponding bit to the neuron/node having the highest activation will be high/true.
- Returns:
The one-hot output activations array.
- Return type:
numpy.array
- train(training_data, targets, batch_size, epochs, optimizer, testing_data=None, testing_targets=None, testing_freq=1, decay_freq=1)
Trains the model on the training data, after training is complete, you can call
plot_performance()to plot performance graphs.- Parameters:
training_data (numpy.array) – numpy array containing training data.
targets (numpy.array) – numpy array containing training targets, corresponding to the training data.
batch_size (int) – Number of training examples to use in one epoch, or number of training examples to use to estimate the gradient.
epochs (int) – Number of epochs the model should be trained for.
optimizer (any Optimizer object) – See Optimizers
testing_data (numpy.array) – numpy array containing testing data.
testing_targets (numpy.array) – numpy array containing testing targets, corresponding to the testing data.
testing_freq (int) – How frequently the model should be tested, i.e the model will be tested after every
testing_freqepochs. You may want to increase this to reduce training time.decay_freq (int) – How frequently the model should decay the learning rate. The learning rate will decay after every
decay_freqepochs.
- Raises:
ValueError – If
training_data,targets,testing_dataortesting_targetshas invalid dimensions/shape.
- cost(testing_data, testing_targets)
Tests the average cost of the model on the testing data passed to the function.
- Parameters:
testing_data (numpy.array) – numpy array containing testing data.
testing_targets (numpy.array) – numpy array containing testing targets, corresponding to the testing data.
- Returns:
cost – The average cost of the model over the testing data.
- Return type:
float
- Raises:
ValueError – If
testing_dataortesting_targetshas invalid dimensions/shape.
- accuracy(testing_data, testing_targets)
Tests the accuracy of the model on the testing data passed to the function. This function should be only used for classification.
- Parameters:
testing_data (numpy.array) – numpy array containing testing data.
testing_targets (numpy.array) – numpy array containing testing targets, corresponding to the testing data.
- Returns:
accuracy – The accuracy of the model over the testing data i.e how many testing examples did the model predict correctly.
- Return type:
float
- confusion_matrix(test_data, test_targets, gnames=[], plot=True)
Returns and plots confusion matrix on the given test data.
- Parameters:
test_data (numpy.array) – Numpy array containing test data
test_targets (numpy.array) – Numpy array containing the targets corresponding to the test data.
plot (bool) – If set to false, will not plot the matrix. Default is true.
gnames (list) – List of string names for each class/group.
- Returns:
confusion_matrix – The confusion matrix.
- Return type:
numpy.array
Gaussian Kernel
- pykitml.gaussian_kernel(input_data, training_inputs, sigma=1)
Transforms the give input data using the gaussian kernel.
- Parameters:
input_data (numpy.array) – The input data points to transform.
training_inputs (numpy.array) – The training data.
sigma (float) – Hyperparameter that determines the ‘spread’ of the kernel.
Example: Classifying Iris Using SVM with Linear Kernel
Dataset
Iris - pykitml.datasets.iris module
Training
import numpy as np
import pykitml as pk
from pykitml.datasets import iris
# Load iris data set
inputs_train, outputs_train, inputs_test, outputs_test = iris.load()
# Format the outputs for svm training, zeros to -1
svm_outputs_train = np.where(outputs_train == 0, -1, 1)
svm_outputs_test = np.where(outputs_test == 0, -1, 1)
# Create model
svm_iris_classifier = pk.SVM(4, 3)
# Train the model
svm_iris_classifier.train(
training_data=inputs_train,
targets=svm_outputs_train,
batch_size=20,
epochs=1000,
optimizer=pk.Adam(learning_rate=3, decay_rate=0.95),
testing_data=inputs_test,
testing_targets=svm_outputs_test,
testing_freq=30,
decay_freq=10
)
# Save it
pk.save(svm_iris_classifier, 'svm_iris_classifier.pkl')
# Print accuracy
accuracy = svm_iris_classifier.accuracy(inputs_train, outputs_train)
print('Train accuracy:', accuracy)
accuracy = svm_iris_classifier.accuracy(inputs_test, outputs_test)
print('Test accuracy:', accuracy)
# Plot performance
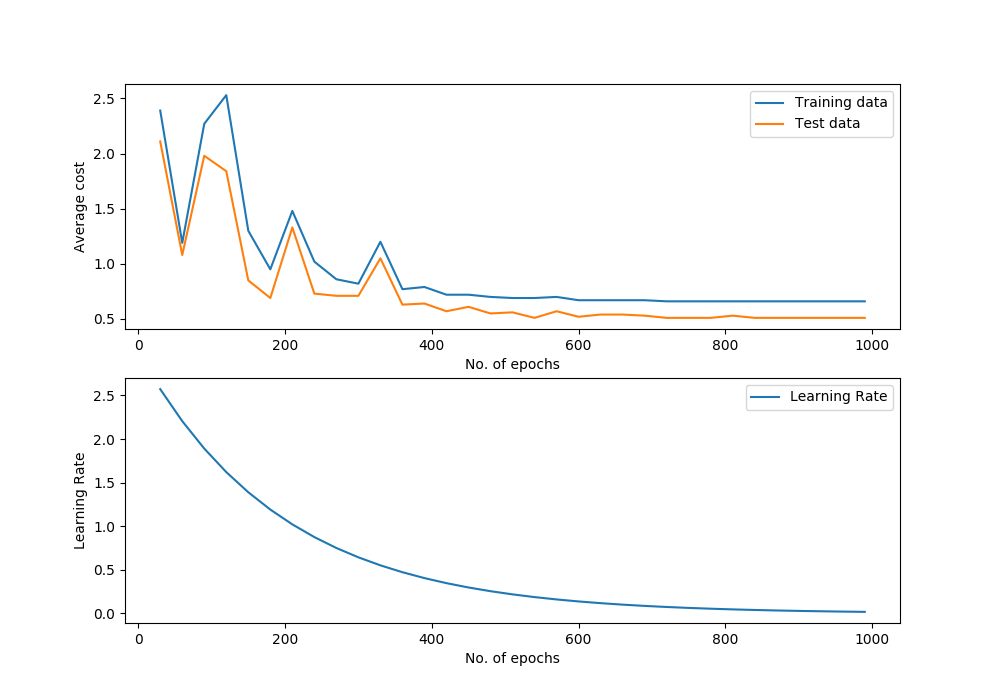
svm_iris_classifier.plot_performance()
# Plot confusion matrix
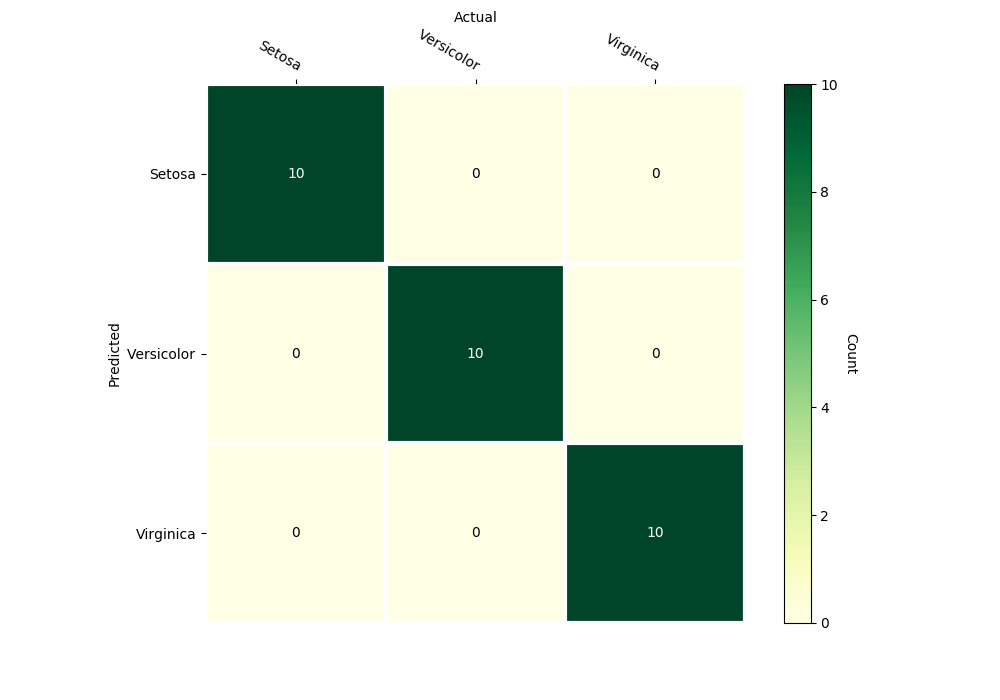
svm_iris_classifier.confusion_matrix(inputs_test, outputs_test,
gnames=['Setosa', 'Versicolor', 'Virginica'])
Predict type of species with sepal-length, sepal-width, petal-length, petal-width: 5.8, 2.7, 3.9, 1.2
import numpy as np
import pykitml as pk
# Predict type of species with
# sepal-length sepal-width petal-length petal-width
# 5.8, 2.7, 3.9, 1.2
input_data = np.array([5.8, 2.7, 3.9, 1.2])
# Load the model
svm_iris_classifier = pk.load('svm_iris_classifier.pkl')
# Get output
svm_iris_classifier.feed(input_data)
model_output = svm_iris_classifier.get_output_onehot()
# Print result
print(model_output)
Performance Graph
Confusion Matrix
Example: Handwritten Digit Recognition (MNIST) using Gaussian Kernel
Dataset
MNIST - pykitml.datasets.mnist module
Training
import os.path
import numpy as np
import pykitml as pk
from pykitml.datasets import mnist
# Download dataset
if not os.path.exists('mnist.pkl'):
mnist.get()
# Load mnist data set
inputs_train, outputs_train, inputs_test, outputs_test = mnist.load()
# Train on only first 10000
inputs_train = inputs_train[:10000]
outputs_train = outputs_train[:10000]
# Transform inputs using gaussian kernal
sigma = 3.15
gaussian_inputs_train = pk.gaussian_kernel(inputs_train, inputs_train, sigma)
gaussian_inputs_test = pk.gaussian_kernel(inputs_test, inputs_train, sigma)
# Format the outputs for svm training, zeros to -1
svm_outputs_train = np.where(outputs_train == 0, -1, 1)
svm_outputs_test = np.where(outputs_test == 0, -1, 1)
# Create model
svm_mnist_classifier = pk.SVM(gaussian_inputs_train.shape[1], 10)
# Train the model
svm_mnist_classifier.train(
training_data=gaussian_inputs_train,
targets=svm_outputs_train,
batch_size=20,
epochs=1000,
optimizer=pk.Adam(learning_rate=3.5, decay_rate=0.95),
testing_data=gaussian_inputs_test,
testing_targets=svm_outputs_test,
testing_freq=30,
decay_freq=10
)
# Save it
pk.save(svm_mnist_classifier, 'svm_mnist_classifier.pkl')
# Print accuracy
accuracy = svm_mnist_classifier.accuracy(gaussian_inputs_train, outputs_train)
print('Train accuracy:', accuracy)
accuracy = svm_mnist_classifier.accuracy(gaussian_inputs_test, outputs_test)
print('Test accuracy:', accuracy)
# Plot performance
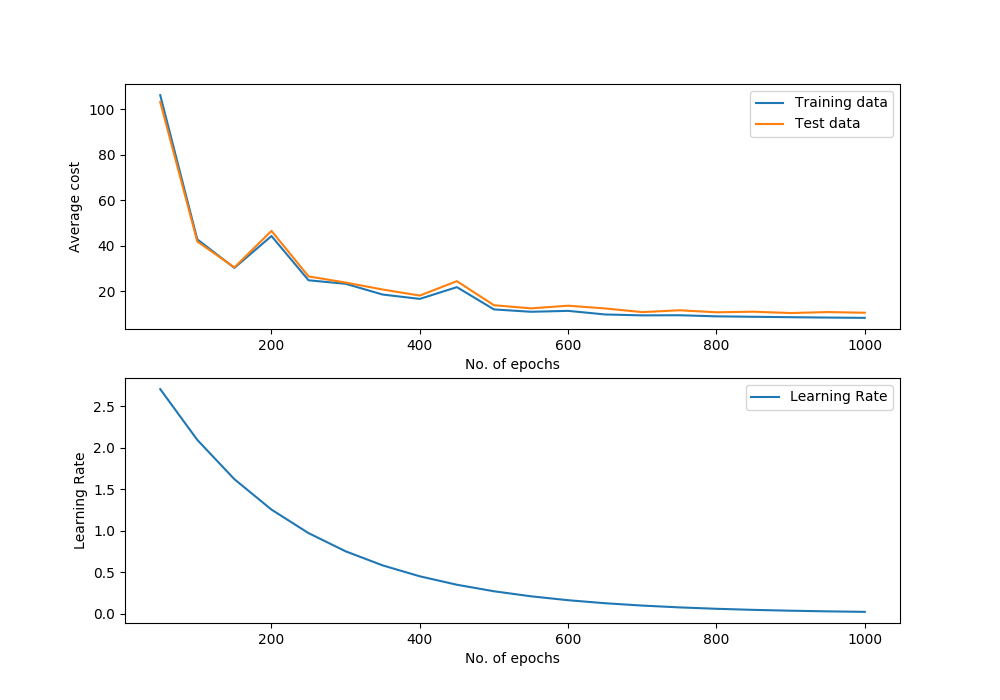
svm_mnist_classifier.plot_performance()
# Plot confusion matrix
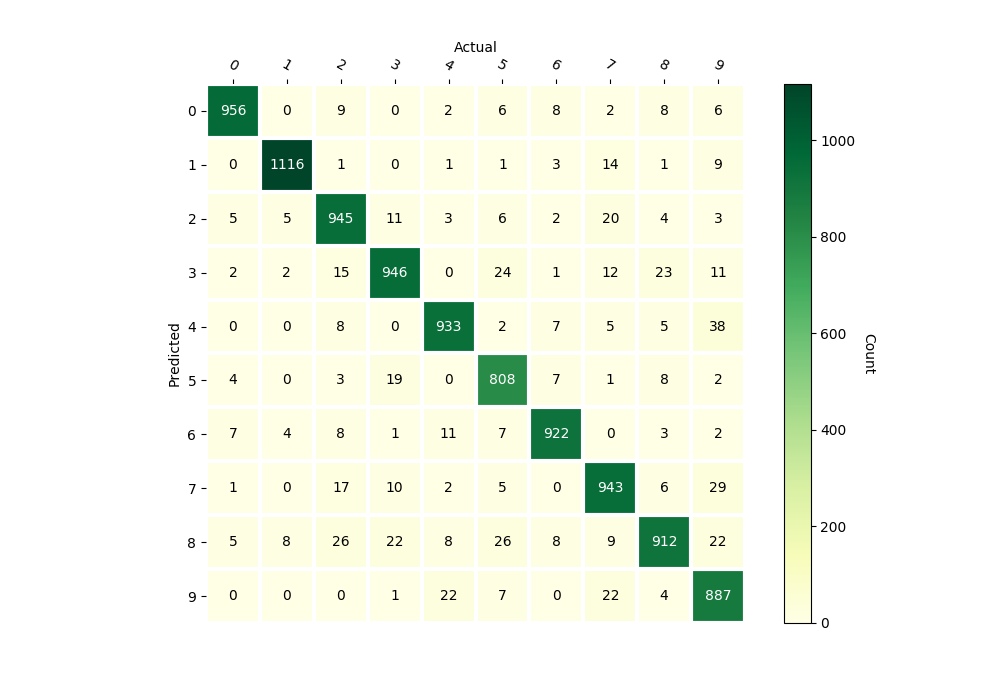
svm_mnist_classifier.confusion_matrix(gaussian_inputs_test, outputs_test)
Predicting
import random
import matplotlib.pyplot as plt
import pykitml as pk
from pykitml.datasets import mnist
# Load dataset
inputs_train, outputs_train, _, _ = mnist.load()
# Use only first 10000
inputs_train = inputs_train[:10000]
outputs_train = outputs_train[:10000]
# Load the trained network
svm_mnist_classifier = pk.load('svm_mnist_classifier.pkl')
# Pick a random example from testing data
index = random.randint(0, 9000)
# Show the test data and the label
plt.imshow(inputs_train[index].reshape(28, 28))
plt.show()
print('Label: ', outputs_train[index])
# Transform the input
input_data = pk.gaussian_kernel(inputs_train[index], inputs_train)
# Show prediction
svm_mnist_classifier.feed(input_data)
model_output = svm_mnist_classifier.get_output_onehot()
print('Predicted: ', model_output)
Performance Graph
Confusion Matrix