Gaussian Naive Bayes
Class Reference
- class pykitml.GaussianNaiveBayes(input_size, output_size)
- __init__(input_size, output_size)
- Parameters:
input_size (int) – Size of input data or number of input features.
output_size (int) – Number of categories or groups.
- feed(input_data)
Accepts input array and feeds it to the model.
- Parameters:
input_data (numpy.array) – The input to feed the model.
- Raises:
ValueError – If the input data has invalid dimensions/shape.
Note
This function only feeds the input data, to get the output after calling this function use
get_output()orget_output_onehot()
- get_output()
Returns the output activations of the model.
- Returns:
The output activations.
- Return type:
numpy.array
- get_output_onehot()
Returns the output layer activations of the model as a one-hot array. A one-hot array is an array of bits in which only one of the bits is high/true. In this case, the corresponding bit to the neuron/node having the highest activation will be high/true.
- Returns:
The one-hot output activations array.
- Return type:
numpy.array
- train(training_data, targets)
Trains the model on the training data.
- Parameters:
training_data (numpy.array) – numpy array containing training data.
targets (numpy.array) – numpy array containing training targets, corresponding to the training data.
- Raises:
numpy.AxisError – If output_size is less than two. Use
pykitml.onehot()to change 0/False to [1, 0] and 1/True to [0, 1] for binary classification.
- accuracy(testing_data, testing_targets)
Tests the accuracy of the model on the testing data passed to the function. This function should be only used for classification.
- Parameters:
testing_data (numpy.array) – numpy array containing testing data.
testing_targets (numpy.array) – numpy array containing testing targets, corresponding to the testing data.
- Returns:
accuracy – The accuracy of the model over the testing data i.e how many testing examples did the model predict correctly.
- Return type:
float
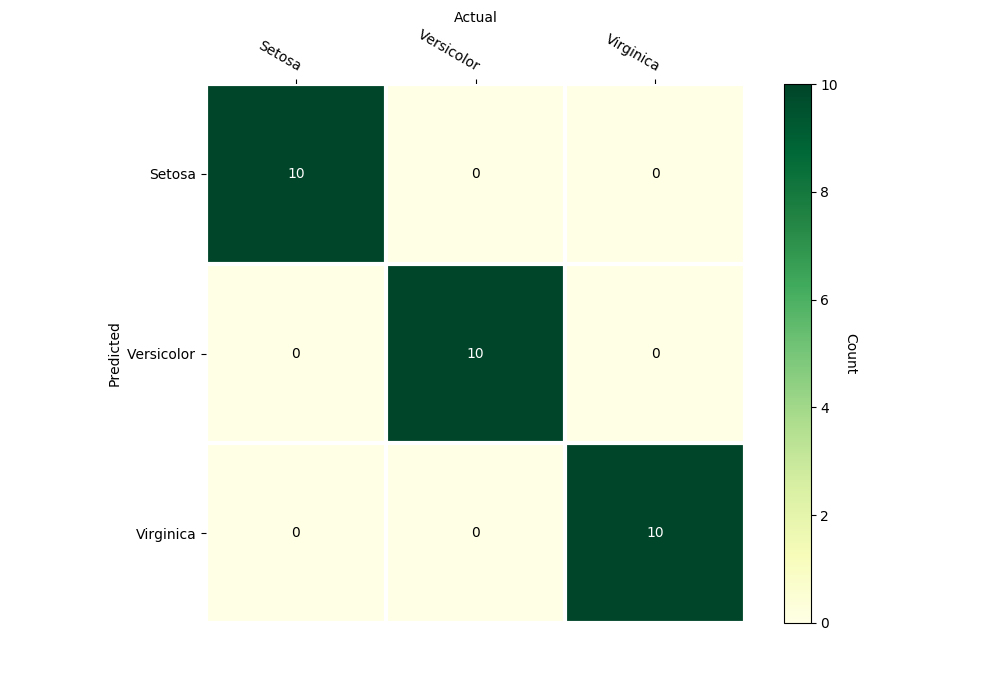
- confusion_matrix(test_data, test_targets, gnames=[], plot=True)
Returns and plots confusion matrix on the given test data.
- Parameters:
test_data (numpy.array) – Numpy array containing test data
test_targets (numpy.array) – Numpy array containing the targets corresponding to the test data.
plot (bool) – If set to false, will not plot the matrix. Default is true.
gnames (list) – List of string names for each class/group.
- Returns:
confusion_matrix – The confusion matrix.
- Return type:
numpy.array
Example: Classifying Iris
Dataset
Iris - pykitml.datasets.iris module
Training
import pykitml as pk
from pykitml.datasets import iris
# Load iris data set
inputs_train, outputs_train, inputs_test, outputs_test = iris.load()
# Create model
bayes_iris_classifier = pk.GaussianNaiveBayes(4, 3)
# Train
bayes_iris_classifier.train(inputs_train, outputs_train)
# Save it
pk.save(bayes_iris_classifier, 'bayes_iris_classifier.pkl')
# Print accuracy
accuracy = bayes_iris_classifier.accuracy(inputs_train, outputs_train)
print('Train accuracy:', accuracy)
accuracy = bayes_iris_classifier.accuracy(inputs_test, outputs_test)
print('Test accuracy:', accuracy)
# Plot confusion matrix
bayes_iris_classifier.confusion_matrix(inputs_test, outputs_test,
gnames=['Setosa', 'Versicolor', 'Virginica'])
Predict type of species with sepal-length, sepal-width, petal-length, petal-width: 5.8, 2.7, 3.9, 1.2
import numpy as np
import pykitml as pk
# Predict type of species with
# sepal-length sepal-width petal-length petal-width
# 5.8, 2.7, 3.9, 1.2
input_data = np.array([5.8, 2.7, 3.9, 1.2])
# Load the model
bayes_iris_classifier = pk.load('bayes_iris_classifier.pkl')
# Get output
bayes_iris_classifier.feed(input_data)
model_output = bayes_iris_classifier.get_output_onehot()
# Print result
print(model_output)
Confusion Matrix