K-Means Clustering
K-Means Function
- pykitml.kmeans(training_data, nclusters, max_iter=1000, trials=50)
Identifies cluster centres on training data using k-means.
- Parameters:
training_data (numpy.array) – Numpy array containing training data.
nclusters (int) – Number of cluster to find.
max_iter (int) – Maximum number of iterations to run per trial.
trials (int) – Number of times k-means should run, each with different random initialization.
- Returns:
clusters (numpy.array) – Numpy array containing cluster centres.
cost (numpy.array) – The cost of converged cluster centres.
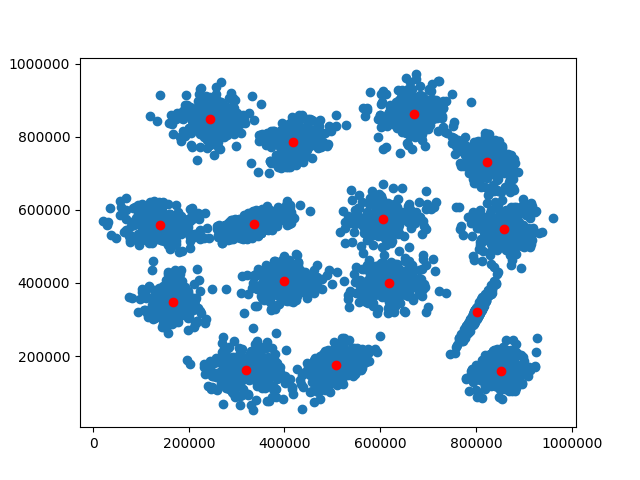
Example: S1 Dataset
Dataset
S1 Clustering - pykitml.datasets.s1clustering module
Training
import os
import pykitml as pk
from pykitml.datasets import s1clustering
import matplotlib.pyplot as plt
# Download the dataset
if not os.path.exists('s1.pkl'):
s1clustering.get()
# Load the dataset
train_data = s1clustering.load()
# Run KMeans
clusters, cost = pk.kmeans(train_data, 15)
# Plot dataset, x and y
plt.scatter(train_data[:, 0], train_data[:, 1])
# Plot clusters, x and y
plt.scatter(clusters[:, 0], clusters[:, 1], c='red')
# Show graph
plt.show()
Scatter Plot