Logistic Regression
Class Reference
- class pykitml.LogisticRegression(input_size, output_size, reg_param=0)
Implements logistic regression for classification.
- __init__(input_size, output_size, reg_param=0)
- Parameters:
input_size (int) – Size of input data or number of input features.
output_size (int) – Number of categories or groups.
reg_param (int) – Regularization parameter for the model, also known as ‘weight decay’.
- feed(input_data)
Accepts input array and feeds it to the model.
- Parameters:
input_data (numpy.array) – The input to feed the model.
- Raises:
ValueError – If the input data has invalid dimensions/shape.
Note
This function only feeds the input data, to get the output after calling this function use
get_output()orget_output_onehot()
- get_output()
Returns the output activations of the model.
- Returns:
The output activations.
- Return type:
numpy.array
- get_output_onehot()
Returns the output layer activations of the model as a one-hot array. A one-hot array is an array of bits in which only one of the bits is high/true. In this case, the corresponding bit to the neuron/node having the highest activation will be high/true.
- Returns:
The one-hot output activations array.
- Return type:
numpy.array
- train(training_data, targets, batch_size, epochs, optimizer, testing_data=None, testing_targets=None, testing_freq=1, decay_freq=1)
Trains the model on the training data, after training is complete, you can call
plot_performance()to plot performance graphs.- Parameters:
training_data (numpy.array) – numpy array containing training data.
targets (numpy.array) – numpy array containing training targets, corresponding to the training data.
batch_size (int) – Number of training examples to use in one epoch, or number of training examples to use to estimate the gradient.
epochs (int) – Number of epochs the model should be trained for.
optimizer (any Optimizer object) – See Optimizers
testing_data (numpy.array) – numpy array containing testing data.
testing_targets (numpy.array) – numpy array containing testing targets, corresponding to the testing data.
testing_freq (int) – How frequently the model should be tested, i.e the model will be tested after every
testing_freqepochs. You may want to increase this to reduce training time.decay_freq (int) – How frequently the model should decay the learning rate. The learning rate will decay after every
decay_freqepochs.
- Raises:
ValueError – If
training_data,targets,testing_dataortesting_targetshas invalid dimensions/shape.
- cost(testing_data, testing_targets)
Tests the average cost of the model on the testing data passed to the function.
- Parameters:
testing_data (numpy.array) – numpy array containing testing data.
testing_targets (numpy.array) – numpy array containing testing targets, corresponding to the testing data.
- Returns:
cost – The average cost of the model over the testing data.
- Return type:
float
- Raises:
ValueError – If
testing_dataortesting_targetshas invalid dimensions/shape.
- accuracy(testing_data, testing_targets)
Tests the accuracy of the model on the testing data passed to the function. This function should be only used for classification.
- Parameters:
testing_data (numpy.array) – numpy array containing testing data.
testing_targets (numpy.array) – numpy array containing testing targets, corresponding to the testing data.
- Returns:
accuracy – The accuracy of the model over the testing data i.e how many testing examples did the model predict correctly.
- Return type:
float
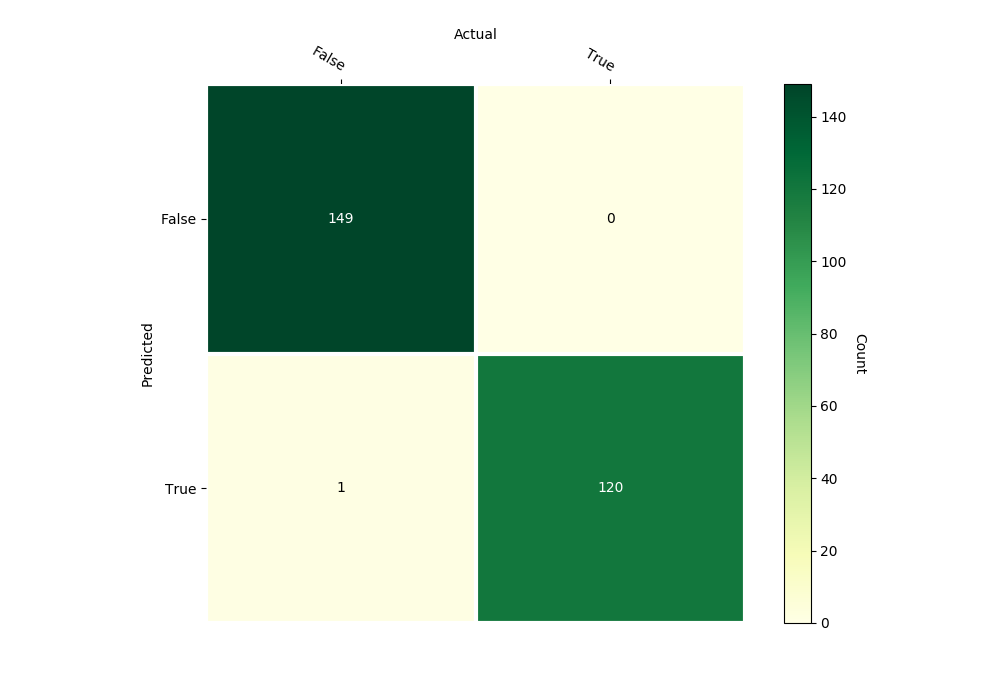
- confusion_matrix(test_data, test_targets, gnames=[], plot=True)
Returns and plots confusion matrix on the given test data.
- Parameters:
test_data (numpy.array) – Numpy array containing test data
test_targets (numpy.array) – Numpy array containing the targets corresponding to the test data.
plot (bool) – If set to false, will not plot the matrix. Default is true.
gnames (list) – List of string names for each class/group.
- Returns:
confusion_matrix – The confusion matrix.
- Return type:
numpy.array
Example: Banknote Authentication
Dataset
Banknote - pykitml.datasets.banknote module
Training
import os.path
import pykitml as pk
from pykitml.datasets import banknote
# Download the dataset
if not os.path.exists('banknote.pkl'):
banknote.get()
# Load banknote data set
inputs_train, outputs_train, inputs_test, outputs_test = banknote.load()
# Normalize dataset
array_min, array_max = pk.get_minmax(inputs_train)
inputs_train = pk.normalize_minmax(inputs_train, array_min, array_max)
inputs_test = pk.normalize_minmax(inputs_test, array_min, array_max)
# Create polynomial features
inputs_train_poly = pk.polynomial(inputs_train)
inputs_test_poly = pk.polynomial(inputs_test)
# Create model
banknote_classifier = pk.LogisticRegression(inputs_train_poly.shape[1], 1)
# Train the model
banknote_classifier.train(
training_data=inputs_train_poly,
targets=outputs_train,
batch_size=10,
epochs=1500,
optimizer=pk.Adam(learning_rate=0.06, decay_rate=0.99),
testing_data=inputs_test_poly,
testing_targets=outputs_test,
testing_freq=30,
decay_freq=40
)
# Save it
pk.save(banknote_classifier, 'banknote_classifier.pkl')
# Plot performance
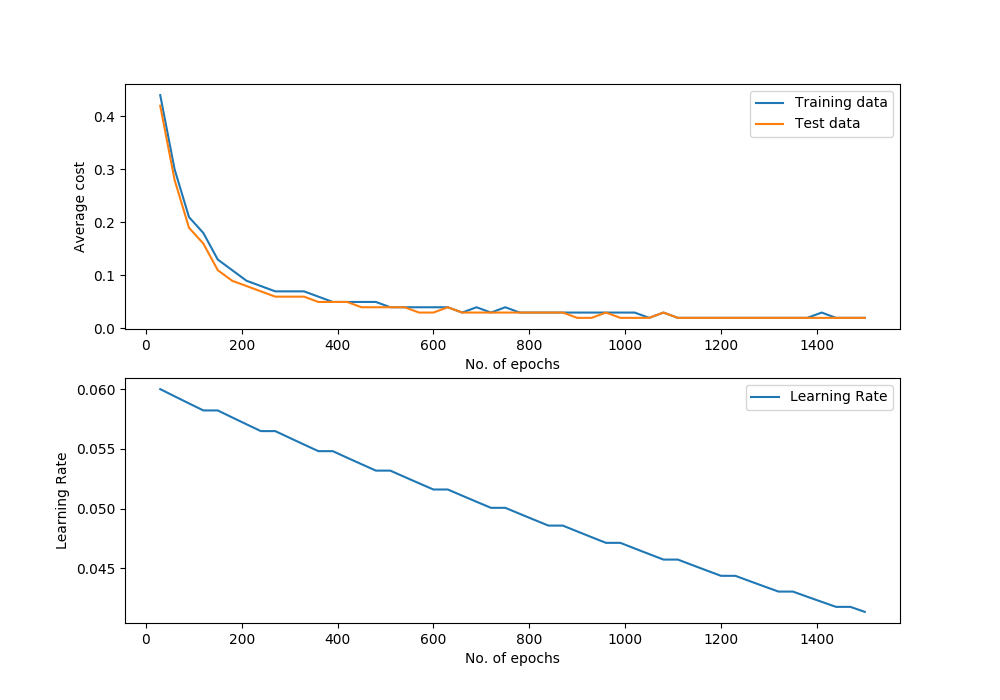
banknote_classifier.plot_performance()
# Print accuracy
accuracy = banknote_classifier.accuracy(inputs_train_poly, outputs_train)
print('Train accuracy:', accuracy)
accuracy = banknote_classifier.accuracy(inputs_test_poly, outputs_test)
print('Test accuracy:', accuracy)
# Plot confusion matrix
banknote_classifier.confusion_matrix(inputs_test_poly, outputs_test)
Predict banknote validity with variance, skewness, curtosis, entropy: -2.3, -9.3, 9.37, -0.86
import numpy as np
import pykitml as pk
from pykitml.datasets import banknote
# Predict banknote validity with variance, skewness, curtosis, entropy
# of -2.3, -9.3, 9.37, -0.86
# Load banknote data set
inputs_train, _, _, _ = banknote.load()
# Load the model
banknote_classifier = pk.load('banknote_classifier.pkl')
# Normalize the inputs
array_min, array_max = pk.get_minmax(inputs_train)
input_data = pk.normalize_minmax(np.array([-2.3, -9.3, 9.37, -0.86]), array_min, array_max)
# Create polynomial features
input_data_poly = pk.polynomial(input_data)
# Get output
banknote_classifier.feed(input_data_poly)
model_output = banknote_classifier.get_output()
# Print result
print(model_output)
Performance Graph
Confusion Matrix