Random Forest
Class Reference
- class pykitml.RandomForest(input_size, output_size, feature_type=[], max_depth=6, min_split=2, max_splits_eval=100, regression=False)
- __init__(input_size, output_size, feature_type=[], max_depth=6, min_split=2, max_splits_eval=100, regression=False)
- Parameters:
input_size (int) – Size of input data or number of input features.
output_size (int) – Number of categories or groups.
feature_type (list) – List of string describing the type of feature for each column. Can be
'continues','ranked', or'categorical'.max_depth (int) – The maximum depth the trees can grow to.
min_split (int) – The minimum number of data points a node should have to get split.
max_splits_eval (int) – The maximum number of split points to evaluate for an attribute. If the number of candidate split points exceed this,
max_splits_evalsplit candidates will be randomly sampled from the candidates and only the sampled ones will be evaluated from finding the best split point.regression (bool) – If the tree is being trained on a regression problem.
- Raises:
InvalidFeatureType – Invalid/Unknown feature type. Can only be
'continues','ranked', or'categorical'.
- feed(input_data)
Accepts input array and feeds it to the model.
- Parameters:
input_data (numpy.array) – The input to feed the model.
- Raises:
ValueError – If the input data has invalid dimensions/shape.
Note
This function only feeds the input data, to get the output after calling this function use
get_output()orget_output_onehot()
- get_output()
Returns the output activations of the model.
- Returns:
The output activations.
- Return type:
numpy.array
- get_output_onehot()
Returns the output layer activations of the model as a one-hot array. A one-hot array is an array of bits in which only one of the bits is high/true. In this case, the corresponding bit to the neuron/node having the highest activation will be high/true.
- Returns:
The one-hot output activations array.
- Return type:
numpy.array
- train(inputs, outputs, num_trees=100, num_feature_bag=None)
Trains the model on the training data.
- Parameters:
training_data (numpy.array) – numpy array containing training data.
targets (numpy.array) – numpy array containing training targets, corresponding to the training data.
num_trees (int) – Number of trees to grow.
num_feature_bag (int or None) – Number of random features to select when growing a tree. If
None(default),ceil(sqrt(input_size))is chosen for classification andint(input_size/3)for regression.
- Raises:
numpy.AxisError – If output_size is less than two. Use
pykitml.onehot()to change 0/False to [1, 0] and 1/True to [0, 1] for binary classification.
- accuracy(testing_data, testing_targets)
Tests the accuracy of the model on the testing data passed to the function. This function should be only used for classification.
- Parameters:
testing_data (numpy.array) – numpy array containing testing data.
testing_targets (numpy.array) – numpy array containing testing targets, corresponding to the testing data.
- Returns:
accuracy – The accuracy of the model over the testing data i.e how many testing examples did the model predict correctly.
- Return type:
float
- r2score(testing_data, testing_targets)
Return R-squared or coefficient of determination value.
- Parameters:
testing_data (numpy.array) – numpy array containing testing data.
testing_targets (numpy.array) – numpy array containing testing targets, corresponding to the testing data.
- Returns:
r2score – The average cost of the model over the testing data.
- Return type:
float
- Raises:
ValueError – If
testing_dataortesting_targetshas invalid dimensions/shape.
- confusion_matrix(test_data, test_targets, gnames=[], plot=True)
Returns and plots confusion matrix on the given test data.
- Parameters:
test_data (numpy.array) – Numpy array containing test data
test_targets (numpy.array) – Numpy array containing the targets corresponding to the test data.
plot (bool) – If set to false, will not plot the matrix. Default is true.
gnames (list) – List of string names for each class/group.
- Returns:
confusion_matrix – The confusion matrix.
- Return type:
numpy.array
- trees
A list of decision trees used in the forest.
Example: Banknote Authentication
Dataset
Banknote - pykitml.datasets.banknote module
Training
import os
import pykitml as pk
from pykitml.datasets import banknote
# Download the dataset
if not os.path.exists('banknote.pkl'):
banknote.get()
# Load heart data set
inputs_train, outputs_train, inputs_test, outputs_test = banknote.load()
# Change 0/False to [1, 0]
# Change 1/True to [0, 1]
outputs_train = pk.onehot(outputs_train)
outputs_test = pk.onehot(outputs_test)
# Create model
ftypes = ['continues']*4
forest_banknote_classifier = pk.RandomForest(4, 2, max_depth=9, feature_type=ftypes)
# Train
forest_banknote_classifier.train(inputs_train, outputs_train)
# Save it
pk.save(forest_banknote_classifier, 'forest_banknote_classifier.pkl')
# Print accuracy
accuracy = forest_banknote_classifier.accuracy(inputs_train, outputs_train)
print('Train accuracy:', accuracy)
accuracy = forest_banknote_classifier.accuracy(inputs_test, outputs_test)
print('Test accuracy:', accuracy)
# Plot confusion matrix
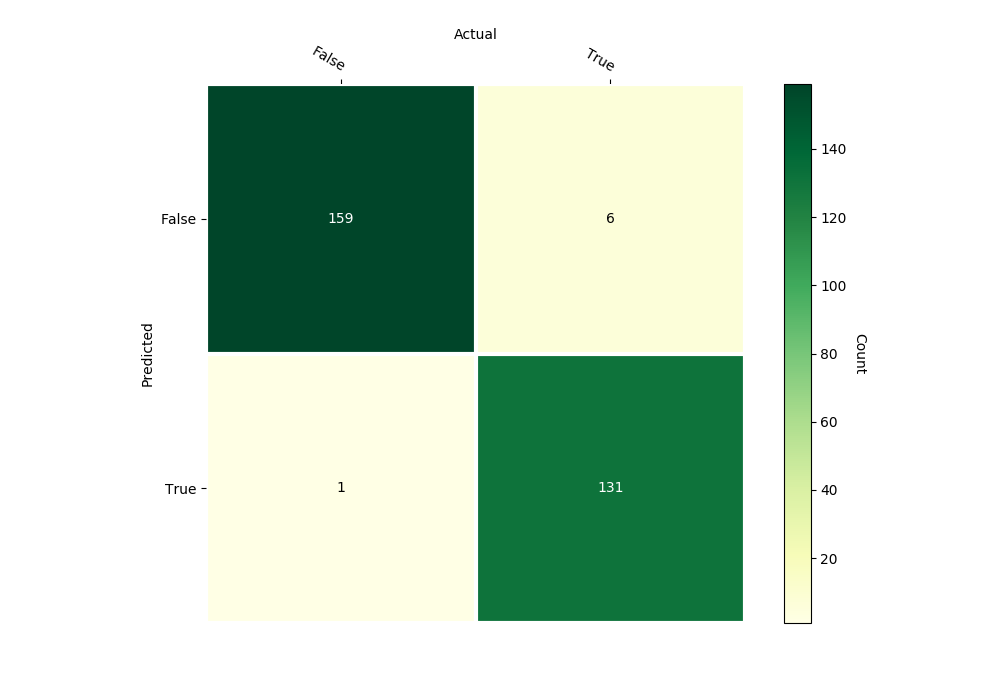
forest_banknote_classifier.confusion_matrix(inputs_test, outputs_test,
gnames=['False', 'True'])
Predict banknote validity with variance, skewness, curtosis, entropy: -2.3, -9.3, 9.37, -0.86
import numpy as np
import pykitml as pk
# Predict banknote validity with variance, skewness, curtosis, entropy
# of -2.3, -9.3, 9.37, -0.86
input_data = np.array([-2.3, -9.3, 9.37, -0.86])
# Load the model
forest_banknote_classifier = pk.load('forest_banknote_classifier.pkl')
# Get output
forest_banknote_classifier.feed(input_data)
model_output = forest_banknote_classifier.get_output()
# Print result
print(model_output)
Confusion Matrix
Example: Heart Disease Prediction
Dataset
Heart Disease - pykitml.datasets.heartdisease module
Training
import os.path
import pykitml as pk
from pykitml.datasets import heartdisease
# Download the dataset
if not os.path.exists('heartdisease.pkl'):
heartdisease.get()
# Load heart data set
inputs, outputs = heartdisease.load()
outputs = pk.onehot(outputs)
# Create model
ftypes = [
'continues', 'categorical', 'categorical',
'continues', 'continues', 'categorical', 'categorical',
'continues', 'categorical', 'continues', 'categorical',
'categorical', 'categorical'
]
forest_heart_classifier = pk.RandomForest(13, 2, max_depth=8, feature_type=ftypes)
# Train
forest_heart_classifier.train(inputs, outputs)
# Save it
pk.save(forest_heart_classifier, 'forest_heart_classifier.pkl')
# Print accuracy
accuracy = forest_heart_classifier.accuracy(inputs, outputs)
print('Accuracy:', accuracy)
# Plot confusion matrix
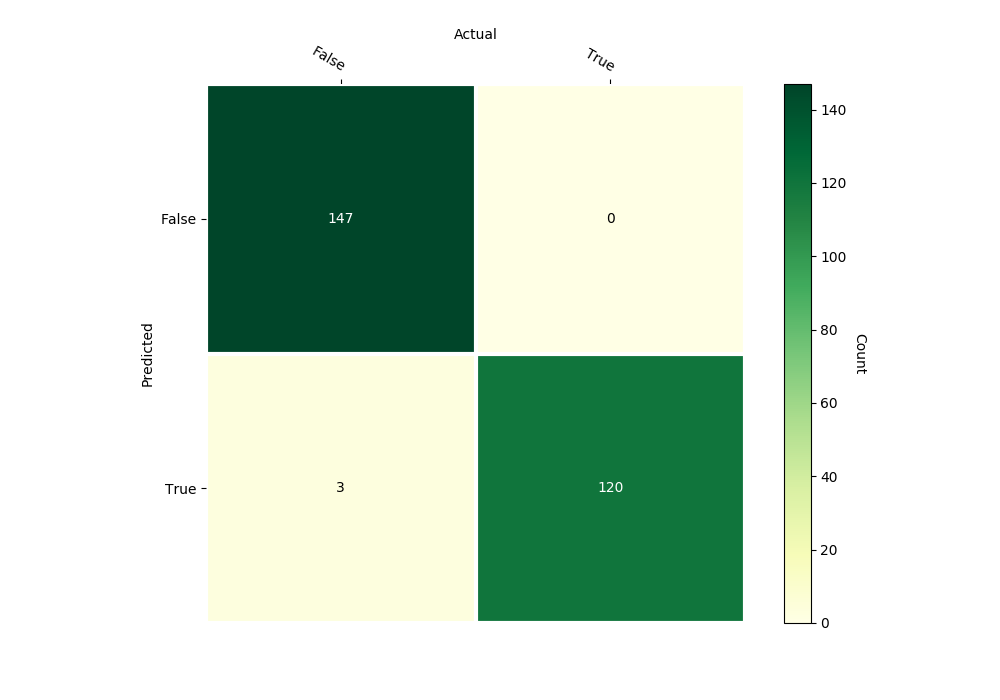
forest_heart_classifier.confusion_matrix(inputs, outputs,
gnames=['False', 'True'])
Predict heartdisease for a person with age, sex, cp, trestbps, chol, fbs, restecg, thalach, exang, oldpeak, slope, ca, thal: 67, 1, 4, 160, 286, 0, 2, 108, 1, 1.5, 2, 3, 3
import numpy as np
import pykitml as pk
# Predict heartdisease for a person with
# age sex cp trestbps chol fbs restecg thalach exang oldpeak slope ca thal
# 67, 1, 4, 160, 286, 0, 2, 108, 1, 1.5, 2, 3, 3
input_data = np.array([67, 1, 4, 160, 286, 0, 2, 108, 1, 1.5, 2, 3, 3], dtype=float)
# Load the model
forest_heart_classifier = pk.load('forest_heart_classifier.pkl')
# Get output
forest_heart_classifier.feed(input_data)
model_output = forest_heart_classifier.get_output()
# Print result (log of probabilities)
print(model_output)
Confusion Matrix